
Set은 어떻게 중복을 제거할까?
알고리즘 문제들을 풀다가 여러가지 자료구조들을 사용하면 왜 빨라지는지 궁금해졌다. 어떤 자료구조를 사용하면 빨라지는지까진 어렴풋이 알고 있는데, 왜 그 자료구조는 빠를 수 있는지가 갑자기 궁금해졌다.
여러가지 자료구조 중에서도 오늘은 Set이 어떻게 해서 중복을 허용하지 않고, 빠를 수 있는지를 알아봤다.
이 부분이 궁금했던 이유는 옛날에 풀었던 단어 정렬 알고리즘 문제에서, 중복을 허용하지 않는 집합을 만들기 위해 List와 Set을 둘 다 사용해봤을 때 결과가 꽤 많이 차이가 났기 때문이다. 공교롭게도 작년 오늘 날짜에 풀었던 문제이다..🙎♀️
먼저 Set을 구현한 구현체들을 살펴봤다. Set의 구현체로는 대표적으로 TreeSet과 HashSet이 있다.
HashSet
HashSet은 Set Collection에서 가장 많이 사용되는 클래스 중 하나이다. 이름처럼 Hash 알고리즘을 사용해서 검색 속도가 엄청 빠르다. HashSet의 내부 코드를 보면, HashMap을 사용해서 값들을 저장한다.
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
// 일부 코드 생략
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
}
HashMap을 사용해서 값을 저장한다면 Hash 알고리즘을 사용해서 값을 검색하고, 값이 존재한다면 중복을 넣지 않기 때문에 HashSet에서 중복인지 빠르게 검색하고 넣지 않는 것 같다. 그렇다면 Hash 알고리즘은 정확히 어떻게 동작하길래 빠르게 값을 검색할 수 있을까?
Hash 알고리즘
Hash 알고리즘은 Hash 함수를 이용해서 Hash 테이블에 저장하고, 다시 그것을 검색하는 알고리즘이다. Hash가 너무 많이 등장하긴 하지만 어떤 함수를 거쳐서 나온 값을 활용해 테이블에 저장하고, 그것을 검색에 활용한다는 뜻이다.
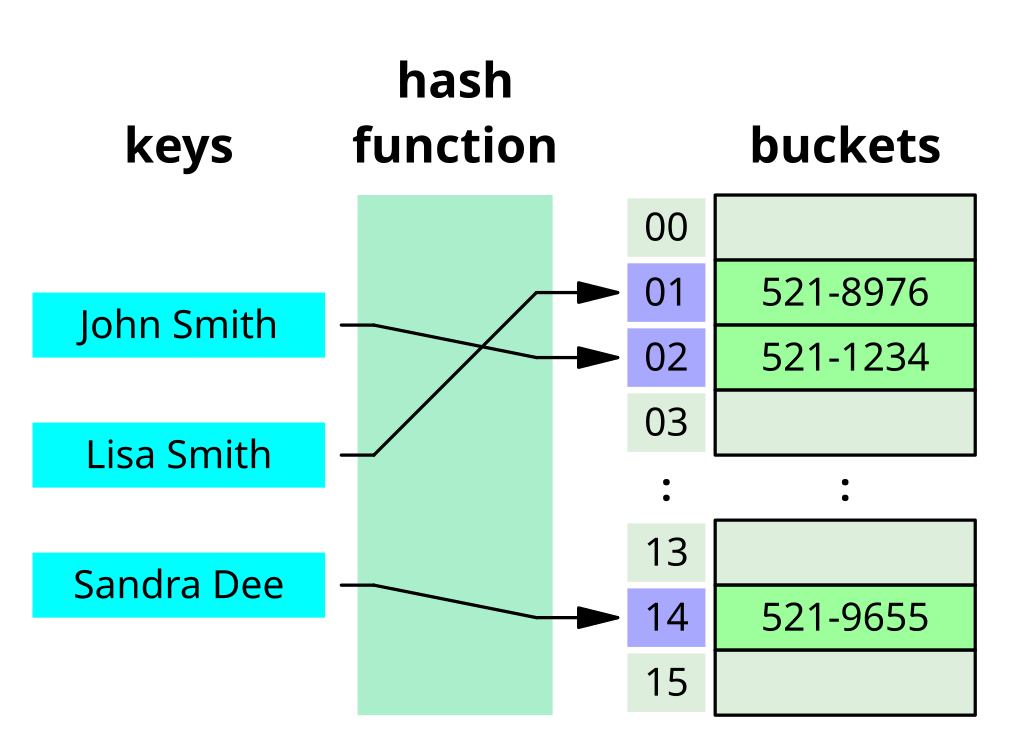
자바에서 Hash 알고리즘을 이용한 자료구조는 Array와 Linked List로 구현되는데, 저장할 데이터의 키 값을 해시 함수에 넣어서 반환되는 값으로 배열의 인덱스를 구하고 인덱스에 저장된 Linked List에 데이터를 저장해서 검색을 빨리 할 수 있게 된다.
정말 간단하게 예를 들어보자면 길이가 10인 배열에 정수를 저장했다고 가정해보자. 여기서 Hash 함수를 거친 값이 10으로 나눈 나머지라고 한다면 1,000,002는 배열의 2번 Index의 Linked List에서 찾을 수 있게 된다.
그래서 실제로 HashSet에서 값을 찾을 때에는 이미 존재하는 요소인지 파악하기 위해서 아래와 같은 과정을 거치게 된다.
- 검색할 값의
hashCode()메소드를 호출해 반환된 해시값으로 검색 범위를 결정한다. (위 이미지라면 Array의 Index를 결정) - 해당 범위의 요소를
equals()메소드로 비교한다. (Array Index에 있는 Linked List들과 값을 비교)
이렇게 값을 비교하는 범위가 현저히 적어지기 때문에 이 문제를 풀었을 때 List를 이용했을 때보다 HashSet을 통해 데이터를 저장하는 방식이 빨라질 수 있었던 것이다.
TreeSet
사실 TreeSet은 한번도 사용해보지 않았다. 주로 HashSet을 많이 사용했었는데, TreeSet도 있다고해서 어떤 때에 사용하는지 알아봤다. TreeSet은 이름에서도 알 수 있듯이, Tree의 형태로 데이터를 저장한다. Tree 중에서도 Binary Search Tree(현재는 향상된 버전, Red-Black Tree)를 이용하기 때문에 데이터가 정렬된 상태로 저장된다.
이 또한 Tree를 사용하기 때문에 검색의 범위를 줄일 수 있어 빠르다. 예를 들어 Binary Search Tree는 Root Node를 기준으로 좌측은 작은 값, 우측은 큰 값을 저장한다. 때문에 좀 더 빠르게 데이터를 검색할 수 있어서 중복된 값이 있는지도 빨리 찾아낼 수 있게 된다.
TreeSet은 데이터가 정렬되어 저장되기 때문에 중복되지 않은 데이터들이 정렬된 상태로 필요할 경우 TreeSet을 사용하는 것 같다.
숫자와 같은 경우에는 쉽게 비교할 수 있지만, 객체를 저장할 경우 정렬 기준이 없으므로 Comparable, Comparator를 제공해 객체를 비교할 방법을 알려줘야한다.
TreeSet도 HashSet과 마찬가지로 내부코드를 보면, TreeMap을 이용해 값을 저장하고 있다.
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
// 일부 코드 생략
private transient NavigableMap<E,Object> m;
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<E,Object>());
}
이렇게 Set이 어떻게해서 List보다 더 빨리 중복된 값을 찾아서 빠른 결과를 보여줄 수 있었는지 알아봤다. 어찌보면 누군가에겐 당연한 결과였을 것 같다. 당연히 List는 전체를 한번 더 보게 되니까 느린거 아니야? 라고 생각하겠지만 Set은 그렇다면 어떻게 전체를 검색하지 않고 중복된 값을 찾지 않는지가 알고 싶었다.
자료구조는 처음에 어렵기만 한 존재라고 생각했는데, 알고리즘을 풀수록 어떻게 이런 생각을 해서 이렇게 빠르게 만들 수 있었을지 이걸 개발한 사람들이 정말 대단하고 재밌기도 하다. 앞으로의 개발에 오늘의 공부가 조금이나마 도움이 되었길 바란다.😊
다음 궁금증이 생길 때 또 돌아오겠습니다!
도움을 준 곳
- TCPSchool_Set 컬렉션 클래스
- 자바 내부 코드